Introduction
We are entering a unique period in the history of business where technologies are rapidly converging to enable the next leap
forward in data warehousing - the ability to affordably keep all business data accessible to the warehouse -
forever.
The amount of business data is exploding at an unprecedented rate. Businesses are retaining enormous amounts of detailed data
such as call detail records, transaction history, and web click-stream and mining it to identify business value. Regulatory and
legal retention requirements are leading businesses to keep years and years of historical data accessible to the warehouse.
Since its inception, Teradata has been the number one choice for the largest data warehouses in existence. As we enter the era of
petabyte scale data warehouses, advanced technologies such as data compression and high-density bulk disk drives are enabling
Teradata to augment its lead in very large data warehouses and to make it cost effective to keep enormous data volumes in the
warehouse.
The trend among customers of Teradata is to introduce more and more applications via Teradata and to retain history data for
longer periods of time. This trend is paced by the affordability of massive warehouses. By recognizing that the performance
requirements for data managed by the warehouse is varied, we can bring technologies to bear that will reduce the effective price of
massive data warehouses.
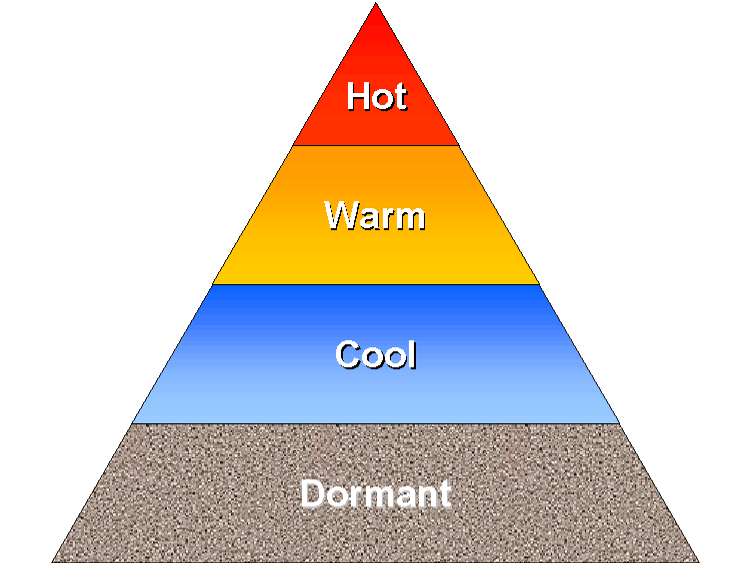 Many customers have varied performance requirements for time-based or history data. Recent data may be accessed frequently, while
older data is accessed less often. Let's use hot, warm, cool, and dormant to describe the average access rate of different classes
of data. In a warehouse with massive history, the volume of data will typically be inversely proportional to the data usage. In
other words, there will be an enormous amount of cool history data that is accessed lightly, and relatively less volume of hot and
warm data that is accessed frequently. The temperature of the data reflects the access rate to that data. The best
storage for hot, warm, and cool data is online disk that is directly accessible to the data warehouse. Truly dormant data is a
candidate for alternative storage - such as tape, optical, or perhaps holographic storage in the future.
Many customers have varied performance requirements for time-based or history data. Recent data may be accessed frequently, while
older data is accessed less often. Let's use hot, warm, cool, and dormant to describe the average access rate of different classes
of data. In a warehouse with massive history, the volume of data will typically be inversely proportional to the data usage. In
other words, there will be an enormous amount of cool history data that is accessed lightly, and relatively less volume of hot and
warm data that is accessed frequently. The temperature of the data reflects the access rate to that data. The best
storage for hot, warm, and cool data is online disk that is directly accessible to the data warehouse. Truly dormant data is a
candidate for alternative storage - such as tape, optical, or perhaps holographic storage in the future.
We distinguish between data that is classified as "cool" vs. data that is truly dormant. While the cool data may be accessed
lightly on average, it still has temporal hot spots, for example, when doing comparative analysis between time periods. Similarly if
the data model is modified via addition of new columns or if data types are changed, then the data is not dormant. Furthermore, if
the data is periodically accessed to recast the data to make historical data relevant in the current business context, then the data
is not dormant. Dormant data is rarely, if ever, accessed.
Customers want seamless management of data as the query and update frequency, or data temperature, of that data changes over time.
They also want the price of storage to be representative of the changing temperature of the data.
The technologies we can use to reduce the effective price of data warehouse storage when the warehouse contains hot, warm, cool,
and dormant data are:
- High capacity disk drives
- High capacity configurations
- Teradata compression
- Alternative storage for truly dormant data
This white paper focuses on Teradata compression, a technology that both reduces the effective price of logical data storage
capacity, and improves query performance. Customers using Teradata compression in V2R4 have experienced up to 50% capacity savings
and scan performance increases up to 35%.
The Benefits of Compression
Teradata compression reduces storage cost by storing more logical data per unit of physical capacity. Performance is improved
because there is less physical data to retrieve during scan-oriented queries. Performance is further enhanced since data remains
compressed in memory and the Teradata cache can hold more logical rows. The compression algorithm used by Teradata is extremely
efficient and the savings in compute resources from reducing disk accesses more than compensates for the CPU used for compression.
Another way to improve performance is to use the space saved by compression for advanced indexes. All of these benefits will be
explored in the remaining sections of this white paper.
Teradata Compression in V2R4
Teradata uses a lossless compression method. This means that although the data is compacted, there is no loss of
information.
The granularity of Teradata compression is the individual field of a row. This is the finest level of granularity possible
and is superior for query processing, updates, and concurrency. Field compression offers superior performance when compared
to row level or block level compression schemes. Row and block level compression schemes require extraneous work to uncompress the
row or block whenever they might potentially contribute to a result set. Furthermore, field compression allows compression to
be independently optimized for the data domain of each column.
Teradata performs database operations directly on the compressed rows - there is no need to reconstruct a decompressed row for
query processing. Of course, external representations and answer sets include the fully uncompressed results.
In Teradata V2R4, one value in each column can be compressed out of the row body. If the column is nullable, then NULLs are also
compressed. The best candidate for compression is the most frequently occurring value in each column. The compressed value is
stored in the table header. A bit field in each row header indicates whether the field is compressed and whether or not the value is
NULL.
Fixed width fields that are not part of the primary index are candidates for Teradata compression. The following data types are
compressible. The native number of bytes used for each data type is indicated in parenthesis.
- Integer Date (4)
- CHAR (N, where N < 256)
- BYTEINT (1)
- SMALLINT (2)
- INTEGER (4)
- FLOAT/REAL (8)
- DOUBLE (8)
- DECIMAL (1, 2, 4 or 8)
- BYTE (N, where N < 256)
When a column has a frequently occurring value it can be highly compressed. Some examples include the following:
- NULLs
- Zeros
- Default values
- Flags
- Spaces
- Binary indicators (e.g., T/F)
Teradata compression is completely transparent to applications,
ETL, queries and views. Compression is easily specified when tables are created or
columns are added to an existing table. For example, here is the syntax for compressing
a populous city:
CREATE TABLE Properties (
Address VARCHAR(40),
City CHAR(20) COMPRESS ('Chicago'),
StateCode CHAR(2)
);
Compression and the Optimizer
Teradata utilizes a leading edge cost based optimizer. The optimizer evaluates the relative cost of many potential plans and picks
a low cost plan. One of the costs considered is the number of estimated I/O operations needed to execute a plan. Tables using
Teradata compression have fewer physical data blocks and will therefore need less physical I/O operations to accomplish certain
tasks. Hence, the plan chosen by the optimizer for a query operating on compressed tables will be naturally optimized to take
advantage of compression.
How Much Compression?
The amount of space savings for a particular column is determined by the percentage of values that can be compressed and the
column data type.
As discussed earlier, compression is implemented by including a bit field in every row header. There is a tradeoff between the
capacity for adding the bit field and the savings from compression. The following table gives the break-even point for different
field widths. For example, if a column has an integer data type with a field width of 4 bytes, then if the most common value (and
NULLs) occurs more than 3.13% of the time, then compression will reduce the storage needed for that column.
Field Width
(Bytes) |
Break Even
Frequency of Occurrence |
| 1 |
12.50% |
| 2 |
6.25% |
| 3 |
4.17% |
| 4 |
3.13% |
| 5 |
2.50% |
| 6 |
2.08% |
| 7 |
1.79% |
| 8 |
1.56% |
| > 12 |
< 1% |
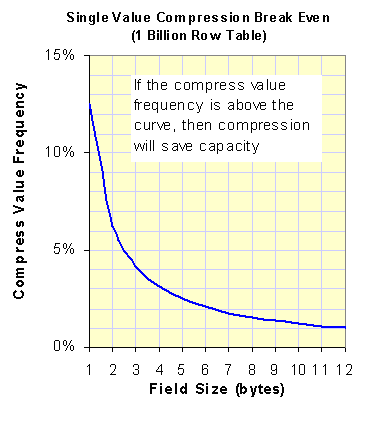
The graph to the above right shows the break-even trendline. As you can see, for any field larger than two bytes, it takes less
than a 5% frequency of occurrence to make compression a winner.
The next question is how much compression will be achieved? The following table shows example compressibility for fields of 1 and
4 bytes. "Percent compression" is the savings when considering the compressed size in comparison to the uncompressed
size.
Field Width
(Bytes) |
Frequency of
Single Value
(and NULL) |
Percent
Compression |
| 1 |
20% |
7% |
| 1 |
50% |
37% |
| 1 |
80% |
67% |
| 4 |
20% |
17% |
| 4 |
50% |
47% |
| 4 |
80% |
77% |
Note that the compression savings are for a particular column. Overall system savings is dependent on the number of columns that
are compressed and the individual savings from each column.
Compression Success Stories
A number of Teradata customers have had huge wins with compression as described in the following customer experiences.
Retail Industry Successes
- 42% capacity savings on four tables, each with over 1 billion rows. The average rows per data block increased by
72%. Biggest capacity savings was compression of decimal zero.
- 58% capacity savings. Table scan and archive times were reduced proportionately. Large capacity savings on single
byte flag fields.
Financial Industry Successes
- 50% capacity savings. Response time improved by 30%.
- 40% capacity savings. Multiload elapsed time decreased by 30%.
Communications Industry Successes
- 50% capacity savings compressing spaces and zeros on a financial application
- 43% capacity savings (over a terabyte) on a table that was initially 2.8 terabytes
- 33% compression on a 50 million row table with over 100 columns compressed. I/O was reduced by 31% on a query mix
and a 7% reduction in CPU was achieved.
- 10% average capacity savings - range of 1% to 37% capacity savings on different tables.
Capacity savings and application performance are not the only winners with Teradata compression. Data maintenance
activities, such as loads, integrity checks, statistics collection, and backups take less time when the data is compressed. Reduced
time and resources for data maintenance yields additional benefit to the end-users in terms of system and application availability
and performance.
Storing Data Efficiently
Teradata compression is one of several techniques available for storing data efficiently. Storage for decimal and integer data
types is a function of the range of values to be accommodated in the field. You can achieve a double win in space savings by using
Teradata compression in conjunction with an efficient decimal or integer size. An example would be to define the decimal range such
that a 4 byte representation was used instead of an 8 byte representation. Then, compression could be used on the most frequently
occurring value.
For character based data, an alternative to Teradata compression is the VARCHAR(N) data type. The number of bytes used to store
each field is the length of the data item plus 2 bytes. Contrast this to a fixed width CHAR(N) data type which takes N bytes per
row, regardless of the actual number of characters in each individual field. Combining Teradata compression with fixed width
character data type can be a very effective space saver.
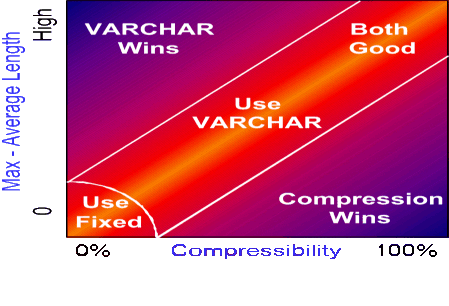 The data demographics will determine whether variable length character data type or fixed width plus compression is more efficient.
The most important factors are:
The data demographics will determine whether variable length character data type or fixed width plus compression is more efficient.
The most important factors are:
- the maximum field length
- the average field length
- the compressibility of the data
Which is best - compression or VARCHAR?
- VARCHAR will be more efficient when the difference of maximum and average field length is high and compressibility is
low.
- Compression and fixed CHAR will be more efficient when the difference of maximum and average field length is low and
compressibility is high.
- When neither is a clear winner, then use VARCHAR since it will use slightly less CPU resource.
Capacity Planning for a New System with Compression
How does the use of Teradata compression affect the capacity planning for a new Teradata system? We must consider both compute and
storage resources to answer this question.
The compute savings from compression are modest, since the database must still execute the application analytics on the logical
data. Therefore, when considering the use of Teradata compression for a new system, the number of compute nodes required for the
workload will be equal to a system without compression.
Compression will reduce the amount of physical storage capacity required for a given amount of logical data. The savings can be
estimated by examining sample data. Teradata compression will result in more cost-effective storage for the warehouse.
Using Reclaimed Capacity on an Existing System
On an existing system, the introduction of compression is unlikely to free up a significant amount of compute resource. On systems
where CPU resource is available, the space savings from compression may allow more applications to be introduced prior to the next
system upgrade. If CPU is fully utilized then we must look for alternative ways to use reclaimed capacity.
One quick and easy way to use this capacity is to keep more infrequently accessed history data online.
Another way to use the capacity is to improve system availability with the use of fallback for all or some tables.
Alternately, the excess capacity can be leveraged to improve performance through the use of advanced index techniques such as:
- Join index
- Aggregate join index
- Covered index
- Value ordered index
Teradata is a strong advocate of a normalized database design. However, in some situations, augmentation of a normalized
base table with raw data extensions may be an effective way to improve performance.
- Pre-joined summary tables
- Pre-aggregated summary tables
- Duplicated vertical or horizontal partitions of the base table
Keep in mind that these de-normalizations will potentially carry significant data maintenance costs. These de-
normalizations will only be effective when the savings from a high query volume more than compensates for the additional data
maintenance.
Put Everything in the Data Warehouse and Keep it Forever
Teradata compression delivers a significant storage savings, while simultaneously improving data warehouse performance, especially
for scan-oriented queries. Compression is fully supported by Teradata's cost based optimizer. The space saved by compression could
be used to reduce storage cost, or to keep more online history, or to further enhance performance with advanced indexing, or to
improve availability with increased use of fallback. Teradata compression is one of many technologies that will enable customers to
put everything in the data warehouse and keep it forever.
| 